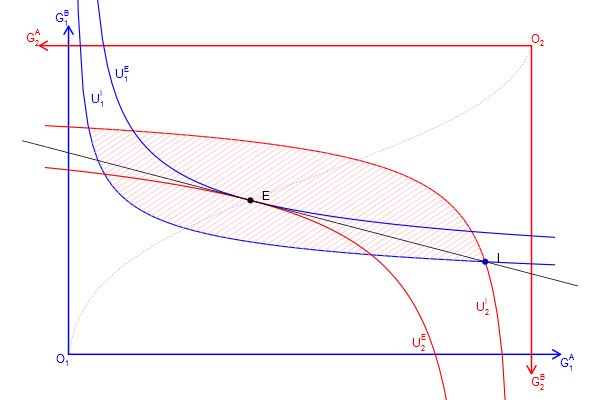
以前に描いたコードを整理しなおしたと言うか、手計算で微分して均衡や契約曲線を求めていたのでどちらかと言うと作り直したものですが、applyやwhichやexpressionなどに慣れるのに良さそうだったので。数値解析で均衡点を求めているので、初期財の配分を変えたり、効用関数を他の凸で連続なモノ(e.g. CES型)に変えても、そこの部分だけの変更でプロットできるはずです。
# 連立方程式を解くのでnleqslvをロード、インストールしていなければインストールしてもらう loadLib <- function(...){ for(lname in unlist(list(...))){ if(!any(suppressWarnings(library(quietly=TRUE, verbose=FALSE)$results[,"Package"] == lname))){ stop(sprintf("Do install.packages(\"%s\") before runnning this script.", lname)) } library(lname, character.only = TRUE) } } loadLib("nleqslv") # 財の配分を表す行列 initial_goods <- matrix(c(0.9, 0.1, 0.3, 0.7), 2, 2, dimnames = list(c("person 1", "person 2"), c("g/s A", "g/s B"))) # トランスログ型効用関数の雛形を定義 U_pt <- function(b, gs_a, gs_b){ # b[3]~b[5]≠0だと局所的に凸なだけなので、安易に財の総量を増やしたり、下手にパラメーターをいじると、計算がデタラメに。 if(gs_a <=0 || gs_b<=0) return(-Inf) as.numeric(b[1]*log(gs_a) + b[2]*log(gs_b) + b[3]*log(gs_a)^2 + b[4]*log(gs_b)^2 + b[5]*log(gs_a)*log(gs_b)) } # Person 1と2の効用関数を定義 U_1 <- function(gs_a, gs_b) U_pt(c(0.4, 0.6, 0, -0.5, 0), gs_a, gs_b) U_2 <- function(gs_a, gs_b) U_pt(c(0.5, 0.5, 0, -0.4, 0), gs_a, gs_b) # 各財/サービスの合計を求めておく sum_of_goods <- apply(initial_goods, 2, sum) # グラディエントを数値解析 dU <- function(U, gs_a, gs_b, h=1e-4){ r <- c(U(gs_a + h, gs_b) - U(gs_a - h, gs_b), U(gs_a, gs_b + h) - U(gs_a, gs_b - h)) / (2*h) names(r) <- c("d(g/s A)", "d(g/s B)") r } getPrice <- function(goods){ # 限界効用を計算 dU1 <- dU(U_1, goods["person 1", "g/s A"], goods["person 1", "g/s B"]) dU2 <- dU(U_2, goods["person 2", "g/s A"], goods["person 2", "g/s B"]) # 価格と言うか交換レート(限界代替率)を計算 r <- c(dU1["d(g/s A)"]/dU1["d(g/s B)"], dU2["d(g/s A)"]/dU2["d(g/s B)"]) names(r) <- c("person 1", "person 2") r } getDistribution <- function(initial_goods, exchange){ # 財配分を更新 # initial_goods: 初期配分 # exchange: 交換量 goods <- initial_goods goods["person 1", ] <- initial_goods["person 1", ] - exchange goods["person 2", ] <- initial_goods["person 2", ] + exchange goods } getEquilibrium <- function(initial_goods){ # 均衡を計算 r_nleqslv <- nleqslv(c(0.0, -0.0), function(exchange){ goods <- getDistribution(initial_goods, exchange) p <- getPrice(goods) # Person 1とPerson 2の限界代替率が一致し、Person 1の支出と収入が一致する点が均衡 # p*(x0 - x) + (y0 - y) = 0 c(p["person 1"] - p["person 2"], exchange[1]*p["person 1"] + exchange[2]) }) exchange <- r_nleqslv$x goods <- getDistribution(initial_goods, exchange) price <- getPrice(goods) # 分離超平面(式の形にしておく) shpe <- substitute(B0 - a*(A - A0), list(B0=goods[1, 2], a=price[1], A0=goods[1, 1])) list(price=price, exchange=exchange, goods=goods, shp=function(A){ eval(shpe) }) } # 均衡の計算 equilibrium <- getEquilibrium(initial_goods) # 無差別曲線の描画 drawIDC <- function(goods, lwd=c(1.5, 1.5), col=c("blue", "red", "pink"), names=NULL, IsCore=FALSE, density=10){ UL_1 <- U_1(goods["person 1", "g/s A"], goods["person 1", "g/s B"]) UL_2 <- U_2(goods["person 2", "g/s A"], goods["person 2", "g/s B"]) demand_B <- function(UL, U, A){ B <- numeric(length(A)) for(i in 1:length(A)){ r_nlm <- nlm(function(b){ if(b <= 0){ return(1e+6) } (UL - U(A[i], b))^2 }, 1) B[i] <- with(r_nlm, ifelse(code<=3, estimate[1], NA)) } B } # 財Aの量が横軸になる,0は効用関数の定義域から外れるので調整している # 無差別曲線を2つ、片方ひっくり返して重ねている図のため、線が枠をはみ出る方がよいので、上限はあえてずらしてる scale <- 1.05 A <- seq(1e-6, sum_of_goods["g/s A"]*scale, length.out=101) IC_1 <- matrix(c(A, demand_B(UL_1, U_1, A)), length(A), 2) colnames(IC_1) <- c("g/s A", "g/s B") # Person 2の無差別曲線は180度回転してプロットするため、経済全体の財の量からPerson 2の財の量を引いて、対応するPerson 1の財の量を求めてプロットしている IC_2 <- matrix(c(sum_of_goods["g/s A"] - A, sum_of_goods["g/s B"] - demand_B(UL_2, U_2, A)), length(A), 2) colnames(IC_2) <- c("g/s A", "g/s B") lines(IC_1[,"g/s B"] ~ IC_1[,"g/s A"], lwd=lwd[1], col=col[1]) lines(IC_2[,"g/s B"] ~ IC_2[,"g/s A"], lwd=lwd[2], col=col[2]) if(!is.null(names)){ # 描画域の大きさから、表示位置の調整量を決める xadj <- (par()$usr[2] - par()$usr[1])/75 # 枠内で最大のB財の量を求める b <- max(IC_1[ , "g/s B"][IC_1[ , "g/s B"] < sum_of_goods["g/s B"]], na.rm = TRUE) # 最大のB財に対応する行を求める i <- which(IC_1[ , "g/s B"]==b, arr.ind=TRUE) text(IC_1[i, "g/s A"] + xadj, b, names[1], col=col[1], adj=c(0, 1)) # 枠内で最小のB財の量を求める b <- min(IC_2[ , "g/s B"][IC_2[ , "g/s B"] > 0], na.rm = TRUE) # 最小のB財に対応する行を求める i <- which(IC_2[ , "g/s B"]==b, arr.ind=TRUE) text(IC_2[i, "g/s A"] - xadj, b, names[2], col=col[2], adj=c(1, 0)) } # 純粋交換経済のコア # Person 2の無差別曲線(の180度回転)のB財の量よりも、Person 1のB財の量が同じか少ない領域を求める if(IsCore){ # 横軸のIC_1の財Aの量とIC_2の財Aの量の対応がずれているので、線形近似関数をつくる af_1 <- approxfun(IC_1[ , "g/s A"], IC_1[ , "g/s B"]) af_2 <- approxfun(IC_2[ , "g/s A"], IC_2[ , "g/s B"]) # 横軸を細かく取り直す A <- seq(1e-6, sum_of_goods["g/s A"]-1e-6, length.out=100) A <- A[af_1(A) <= af_2(A)] # コアの周回経路を求める x <- c(A, rev(A)) # 行きと帰りは向きが逆 y <- c(af_1(A), af_2(rev(A))) # 行きはPerson 1の無差別曲線に沿って、帰りはPerson 2の〃 # 面を書く関数で色を塗る polygon(x, y, density=density, col=col[3], border=NA) } } # 背景を白に、余白を小さくして、フォントサイズを大きくした設定にする par(bg="white", mar=c(0, 0, 0, 0), cex=1) # 低水準グラフィックス関数で描いて行く plot.new() margin <- 0.1 xlim <- c(-margin, (1 + margin))*sum_of_goods["g/s A"] ylim <- c(-margin, (1 + margin))*sum_of_goods["g/s B"] plot.window(xlim=xlim, ylim=ylim) col <- c("blue", "red") # 枠と言うか矢印を書く with(list(l=0.125, lwd=2), { xlim <- c(-l/2, (1.0 + l/2))*sum_of_goods["g/s A"] ylim <- c(-l/2, (1.0 + l/2))*sum_of_goods["g/s B"] arrows(0.0, 0.0, xlim[2], 0, col=col[1], lwd=lwd, length=l) arrows(0.0, 0.0, 0, ylim[2], col=col[1], lwd=lwd, length=l) arrows(sum_of_goods["g/s A"], sum_of_goods["g/s B"], sum_of_goods["g/s A"], ylim[1], col=col[2], lwd=lwd, length=l) arrows(sum_of_goods["g/s A"], sum_of_goods["g/s B"], xlim[1], sum_of_goods["g/s B"], col=col[2], lwd=lwd, length=l) text(0, 0, expression(O[1]), col=col[1], adj=c(1, 1)) text(xlim[2], 0, expression(G[1]^A), col=col[1], adj=c(0, 1)) text(0, ylim[2], expression(G[1]^B), col=col[1], adj=c(1, 0)) text(sum_of_goods["g/s A"], sum_of_goods["g/s B"], expression(O[2]), col=col[2], adj=c(0, 0)) text(xlim[1], sum_of_goods["g/s B"], expression(G[2]^A), col=col[2], adj=c(1, 0)) text(sum_of_goods["g/s A"], ylim[1], expression(G[2]^B), col=col[2], adj=c(0, 1)) }) # 契約曲線の計算と描画 # 初期時点の組み合わせを格子状に大量に作って計算する grid <- expand.grid( # 0は効用関数の定義域から外れるので調整している "g/s A"=seq(1e-2, 1 - 1e-2, length.out=11) * sum_of_goods["g/s A"], "g/s B"=seq(1e-2, 1 - 1e-2, length.out=11) * sum_of_goods["g/s B"]) # apply関数で行列の列ごとに操作する r_apply <- apply(grid, 1, function(goodsOfPrsn1){ goods <- matrix(c(goodsOfPrsn1, sum_of_goods - goodsOfPrsn1), 2, 2, dimnames=dimnames(initial_goods), byrow=TRUE) equilibrium <- getEquilibrium(goods) with(equilibrium, c(goods["person 1", "g/s A"], goods["person 1", "g/s B"])) }) # 表示する均衡点も契約曲線の点の集合に入れておく r_apply <- cbind(r_apply, with(equilibrium, c(goods["person 1", "g/s A"], goods["person 1", "g/s B"]))) # 行に名前をつけておく rownames(r_apply) <- c("g/s A", "g/s B") # A財の大小で並び替えておく r_apply <- r_apply[, order(r_apply["g/s A", ])] # 直線でつないで契約曲線の近似とする lines(r_apply["g/s A", ], r_apply["g/s B", ], lty=3, col="darkgray") # 初期点を通る無差別曲線を描画 drawIDC(initial_goods, names=c(expression(U[1]^I), expression(U[2]^I)), IsCore=TRUE) with(equilibrium, { # 均衡を通る無差別曲線を描画 drawIDC(goods, col=col, names=c(expression(U[1]^E), expression(U[2]^E))) xadj <- (par()$usr[2] - par()$usr[1])/50 # 文字表示の位置調整 pch <- 21 # 点の形状(21:丸, 22:四角, 23:菱形, 24:三角,25:逆三角, etc...) # 初期配分を描画 points(initial_goods["person 1", "g/s A"], initial_goods["person 1", "g/s B"], pch=pch, col="blue", bg="blue") text(initial_goods["person 1", "g/s A"] + xadj, initial_goods["person 1", "g/s B"], expression(I), adj=c(0, 0)) # 競争均衡点を描画 points(goods["person 1", "g/s A"], goods["person 1", "g/s B"], pch=pch, col="black", bg="black") text(goods["person 1", "g/s A"] + xadj, goods["person 1", "g/s B"], expression(E), adj=c(0, 0)) # 分離超平面を描画 A <- seq(xlim[1], xlim[2], length.out=2) lines(A, shp(A)) }) # 画像ファイルの保存先ディレクトリをつくる img_path <- "img" if(!dir.exists(img_path)){ dir.create(img_path) } # プロットを画像ファイルにコピーして保存 dev.copy(png, file=sprintf("%s/edgeworth_box.png", img_path), width=600, height=400, type="cairo"); dev.off() # , type="cairo"でアンチエイリアス








