ここ20年間ぐらいで地理情報システム(GIS)が一般化し、地理空間データの統計処理も広範囲に行われるようになっており、Rでも地図の表示から(代表的な)地域空間計量モデル(i.e. SLM,SEM,GWR*1))の推定まで簡単に行えるようになりました。
10年ぐらい前はかなり煩雑な処理になる印象があったのですが、今は、地理空間データの操作をsfパッケージで、地理情報からの空間重み行列の作成をspdepfパッケージで、空間重み行列をつかった地域空間計量モデルの推定をspatialregパッケージで、簡潔に出来るようになっています。
この3つのパッケージはvignetteが充実しており*2、英語の解説記事*3はもちろん、日本語の解説も数多い*4のですが、実際にいじらないと感覚がわかないので、初歩的な操作を確認していきます。
パッケージのロード
今回はtidyverseを用います。
loadpkg <- function(pkgs) for(pkg in pkgs){ if(!any(suppressWarnings(library(quietly=TRUE, verbose=FALSE)$results[,"Package"] == pkg))) stop(sprintf("Do install.packages(\"%s\") before runnning this script.", pkg)) library(pkg, character.only = TRUE) } loadpkg(c("tidyverse", "sf", "spdep", "spatialreg"))
データセットのダウンロード
したものを用意したので、国土数値情報ダウンロードサービスから東京都の行政区域データをダウンロードしましょう。
url <- "https://nlftp.mlit.go.jp/ksj/gml/data/N03/N03-2024/N03-20240101_13_GML.zip" fname <- gsub("^.*/", "", url) download.file(url, fname) unzip(fname, exdir = gsub("\\.[^.]+$", "", fname))
役所の都合でウェブのインターフェイスとファイル名は刻々と変化しますが、問題が生じた場合は、対応してください。
なお、今回用いた神社の立地データですが、兼務神社と東京都神社庁の所管ではない神社の方を足すと本務神社の倍ぐらいあり網羅的ではないです*6。
データセットのロード
市区町村ごとのデータでプロットと分析を行うので、市区町村別に神社の数を数えます。
# シェープファイルを読む tokyo_map <- read_sf(file.path("N03-20240101_13_GML", "N03-20240101_13.shp")) # 神社のポイントデータ shrines <- read_csv("https://wh.anlyznews.com/geospatial/shrines.csv", show_col_types = FALSE) %>% mutate(市区町村 = sapply(str_split(.$LocName, "/"), function(x) x[2])) # データセットを作成 tokyo_data <- read_csv("https://wh.anlyznews.com/geospatial/population.csv", comment = "#", show_col_types = FALSE) %>% left_join(shrines %>% count(市区町村, name = "神社数"), join_by(市区町村)) %>% mutate(神社数 = replace_na(神社数, 0)) # 列名を変更 colnames(tokyo_data) <- c("city", "population", "area", "number.of.shrines")
なお、sf::read_sfで読み出したシェープファイルのデータは、sfオブジェクトに格納されます。
sfオブジェクトはsfcオブジェクト(sfオブジェクトの属性sf_columnで指定される列になり、今回はgeometry列)を持つデータフレームで、sfcオブジェクトはsfgオブジェクトのリストになっています。sfgオブジェクトは、点(POINT)線(LINESTRING)面(POLYGON)などの緯度・経度の座標を持つ図形データです。
sfオブジェクトは、列を追加しても、行を削除しても、sfオブジェクトとして扱えます。また、列の対応があっていれば、sfオブジェクトとsfオブジェクトをrbindで連結することもできます。
sfオブジェクトには他に、図形データに紐づいた情報の列を持つことができ、任意に追加することができます。
プロット
東京都の市区町村別(本務)神社密度をプロット
離島も含めると東京都は南北に長すぎるため、表示位置を絞ってプロットします。
# 空間データにデータセットを連結する tokyo_datamap <- tokyo_map %>% left_join(tokyo_data, join_by(N03_004 == city)) # 指定した市区町村の緯度・経度の最大・最小値(Boundary Box)を求める # なお、sfオブジェクトのN03_004列に市区町村名が入っている tokyo_map %>% filter(N03_004 %in% c("奥多摩町", "町田市", "江戸川区")) %>% st_bbox() -> extent_without_remote_islands plot_area <- function(extent, guide = "colourbar") ggplot() + geom_sf(data = tokyo_datamap, aes(fill = number.of.shrines/area), color="darkgray") + scale_fill_gradient(low = "white", high = "blue", guide = guide, name = "神社数/Km²") + coord_sf(xlim = extent[c(1, 3)], ylim = extent[c(2, 4)]) + labs(title = "東京都の市区町村別(本務)神社密度", caption = "東京都神社庁のサイトと東京都の人口(推計)令和6年1月1日より編集", x = NULL, y = NULL) print(plot_area(extent_without_remote_islands))
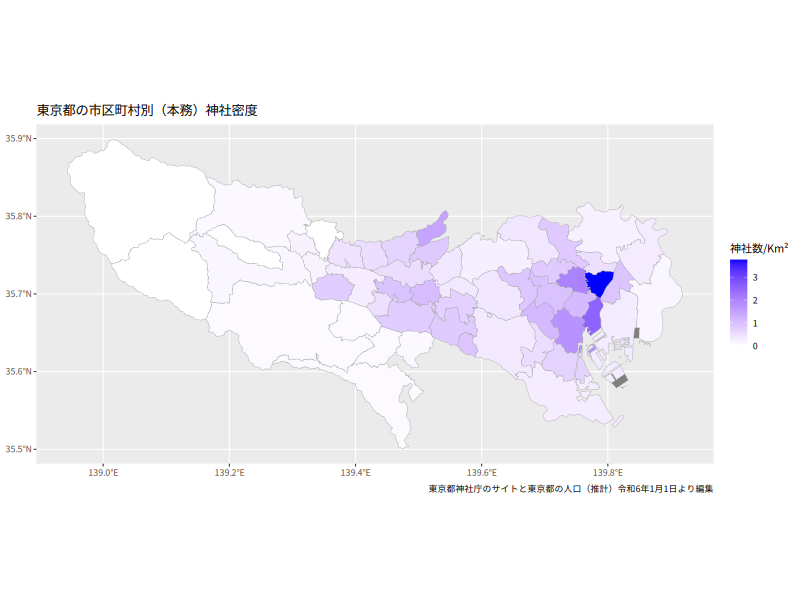
表示範囲を絞っているだけなので、
tokyo_map %>% filter(N03_004 %in% c("三宅村")) %>% st_bbox() %>% plot_area %>% print
とすると、三宅島がプロットできます。

神社のポイントデータのプロット
数が多いのですが、もちろんポイントデータもプロットできます。
plot_points <- function(extent, guide = "colourbar") ggplot() + geom_sf(data = tokyo_datamap, color="darkgray") + geom_point(data = shrines, aes(x = latitude, y = longitude), size = 1) + coord_sf(xlim = extent[c(1, 3)], ylim = extent[c(2, 4)]) + labs(title = "東京都の(本務)神社位置", caption = "東京都神社庁のサイトより編集", x = NULL, y = NULL) print(plot_points(extent_without_remote_islands))

カーネル密度のプロット
上2つのプロットから薄々気づいている人が多いと思いますが、都心部に神社は多いですが、山ひとつと言うわけではないようです。カーネル密度をプロットしてみましょう。
plot_stat_density_2d <- function(extent, guide = "colourbar") ggplot() + geom_sf(data = tokyo_datamap, color="white", bg = "white") + stat_density_2d(data = shrines, aes(x = latitude, y = longitude, fill = after_stat(level)), geom = "polygon") + scale_fill_viridis_c(option="G", direction=-1) + geom_sf(data = tokyo_datamap, color="black", bg = "transparent") + coord_sf(xlim = extent[c(1, 3)], ylim = extent[c(2, 4)]) + labs(title = "東京都の(本務)神社位置", caption = "東京都神社庁のサイトより編集", x = NULL, y = NULL) print(plot_stat_density_2d(extent_without_remote_islands))

地域空間計量モデルの推定
推定に用いるウェイト計算の基礎となる市区町村間のリンク情報を整理したあと、推定します。
データセットの整理
プロットに使った地理情報を統合し、市区町村ごとに一つのレコードにします。また、推定には使えないレコードは削除します。
# 市区町村のポリゴンをひとつに統合する tokyo_map %>% group_by(N03_004) %>% summarize(geometry = st_union(geometry)) %>% st_cast("MULTIPOLYGON") -> union_map # データセットの情報を地理情報に付与 union_map %>% left_join(tokyo_data, join_by(N03_004 == city)) -> tokyo_datamap # 所属未定地は一体として扱われるので、市区町村の連結データをつくるときには除外する。また、連結した地域のない離島も警告およびmoran.mcのエラーの原因になるので除外する。 tokyo_datamap %>% filter(!N03_004 %in% c("所属未定地", "三宅村", "八丈町", "利島村", "大島町", "小笠原村", "御蔵島村", "新島村", "神津島村", "青ヶ島村")) -> nb_datamap
市区町村の連結情報を作成します。
# 連結情報を整理 tokyo_nb <- nb_datamap %>% poly2nb(queen = T) # 連結ウェイトを計算 tokyo_cw <- nb2listw(tokyo_nb, style="W", zero.policy = TRUE)
poly2nbはポリゴンとポリゴンが接している場合は、連結と見なします。tri2nbに変えるとドローネ三角網で連結を測るので、遠隔地があってもカバーしやすくなりますが、今回の離島は遠隔過ぎるので使いません。
nb2listwは、style引数でウェイトのつけ方が変化しますが、取扱説明書に詳細は書いていないようなので、Bなどに変えた場合はtokyo_cw$weightsを観察して何をしているか推察してください。Wの場合は、各地点ごとに、連結先にそれぞれ、1を連結先の数で割ったウェイトがつけられます。
ここまでの手順では生じないはずですが、連結した地域のない市区町村があれば、その名称は以下のようにリストできます。
# 連結した地域のない市区町村があれば、表示する nolinks <- tokyo_nb %>% map_lgl(~ .x[1] == 0) %>% which() if(length(nolinks) > 0) { cat("regions with no links: ", paste(sprintf("\"%s\"", nb_datamap$N03_004[nolinks]), collapse = ", "), "\n") }
どういう連結が計算されたか、図示しておきましょう。
# 離島を除いた境界をつくる(plot用) union_map %>% filter(N03_004 %in% c("奥多摩町", "町田市", "江戸川区")) %>% st_bbox() -> extent_without_remote_islands # 市区町村のポリゴンごとの重心 # 警告t_centroid assumes attributes are constant over geometriesは、sfパッケージ公式ページの例でも出ているので無視 tokyo_centroid <- st_centroid(nb_datamap) # 連結情報を直線の地理情報に変換する(ggplot2用) nb_sf <- nb2lines(tokyo_nb, coords = st_coordinates(tokyo_centroid), proj4string = st_crs(tokyo_map), as_sf = TRUE) # 座標参照系(CRS)を表す属性は、tokyo_mapと同じ地理座標系に設定 plot_area <- function(extent, guide = "colourbar") ggplot() + geom_sf(data = tokyo_datamap, aes(fill = number.of.shrines/area), color="darkgray") + scale_fill_gradient(low = "white", high = "blue", guide = guide, name = "神社数/Km²") + geom_sf(data = nb_sf, color = "red", lwd = 0.3, lty = 2) + geom_sf(data = tokyo_centroid, pch = 19, color = "darkred") + coord_sf(xlim = extent[c(1, 3)], ylim = extent[c(2, 4)]) + labs(title = "東京都の市区町村別(本務)神社密度と市区町村の連結", caption = "東京都神社庁のサイトと東京都の人口(推計)令和6年1月1日より編集", x = NULL, y = NULL) print(plot_area(extent_without_remote_islands))

推定
ここまでくれば、ほとんどOLSと同様に扱えます。
Moran's I統計量
人口密度で回帰したモデルの予測値の残差に、空間的自己相関があるか調べる指標を計算します。
r_lm <- lm(I(number.of.shrines/area) ~ I(population/area), data = nb_datamap) moran.mc(residuals(r_lm), tokyo_cw, nsim = 999, zero.policy = TRUE)
Monte-Carlo simulation of Moran I data: residuals(r_lm) weights: tokyo_cw number of simulations + 1: 1000 statistic = 0.31718, observed rank = 1000, p-value = 0.001 alternative hypothesis: greater
ありますね。
空間ラグモデル(SLM)
観測値を、ある地域の従属変数が周囲の地域の従属変数に影響され、かつ周囲の地域の従属変数もその地域の従属変数に影響される構造にあるときの、均衡状態にあると考えるモデルです。
が説明変数の行列、
が被説明変数のベクトル、
がその係数、
が地理情報に基づくウェイト行列で、
がその係数、
が誤差項です。OLSでは推定できないので、最尤法などでの推定になります。spatialregパッケージだと、最尤法とGLSを組み合わせたEMアルゴリズムになっているようです。
r_slm <- lagsarlm(I(number.of.shrines/area) ~ I(population/area), data = nb_datamap, listw = tokyo_cw, zero.policy = TRUE)
残差に空間的自己相関がありそうではありますが、OLSよりは無さそうです。
moran.mc(residuals(r_slm), tokyo_cw, nsim = 999, zero.policy = TRUE)
Monte-Carlo simulation of Moran I data: residuals(r_slm) weights: tokyo_cw number of simulations + 1: 1000 statistic = 0.081923, observed rank = 915, p-value = 0.085 alternative hypothesis: greater
推定結果は人口密度の係数が大きく動いたりはしませんでした。
summary(r_slm)
Call:lagsarlm(formula = I(number.of.shrines/area) ~ I(population/area),
data = nb_datamap, listw = tokyo_cw, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-0.982718 -0.309705 -0.081939 0.171754 2.357979
Type: lag
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.8949e-02 1.4148e-01 -0.346 0.72935
I(population/area) 3.0813e-05 1.2914e-05 2.386 0.01703
Rho: 0.54447, LR test value: 10.153, p-value: 0.0014403
Asymptotic standard error: 0.13506
z-value: 4.0314, p-value: 5.5452e-05
Wald statistic: 16.252, p-value: 5.5452e-05
Log likelihood: -41.25361 for lag model
ML residual variance (sigma squared): 0.25813, (sigma: 0.50806)
Number of observations: 53
Number of parameters estimated: 4
AIC: 90.507, (AIC for lm: 98.661)
LM test for residual autocorrelation
test value: 4.998, p-value: 0.025377ラグモデルは係数がそのまま効果量にならないわけですが、以下のコマンドで計算できます。
impacts(r_slm, listw = tokyo_cw, R = 999)
Impact measures (lag, exact):
Direct Indirect Total
I(population/area) 3.34282e-05 3.421443e-05 6.764263e-05
空間誤差モデル(SEM)
神社が設置される未知の要因があり、それがある地域だけではなく、周囲の地域にも影響すること、ある地域が周囲の地域から受けた影響が、さらに周囲の地域に(減退しながら)波及していく*7ことを前提にした推定になります。
が説明変数の行列、
が被説明変数のベクトル、
がその係数、
が地理情報に基づくウェイト行列で、
がその係数、
が誤差項です。
と
に
を乗じればOLSで推定できそうなので、GLSだけで推定できそうな気がするのですが、取扱説明書によると、やはり最尤法とGLSを組み合わせたEMアルゴリズムになっているようです。
r_sem <- errorsarlm(I(number.of.shrines/area) ~ I(population/area), data = nb_datamap, listw = tokyo_cw, zero.policy = TRUE) moran.mc(residuals(r_sem), tokyo_cw, nsim = 999, zero.policy = TRUE)
Monte-Carlo simulation of Moran I data: residuals(r_sem) weights: tokyo_cw number of simulations + 1: 1000 statistic = 0.047214, observed rank = 808, p-value = 0.192 alternative hypothesis: greater
summary(r_sem)
Call:errorsarlm(formula = I(number.of.shrines/area) ~ I(population/area),
data = nb_datamap, listw = tokyo_cw, zero.policy = TRUE)
Residuals:
Min 1Q Median 3Q Max
-1.089455 -0.343282 -0.095039 0.172542 2.203251
Type: error
Coefficients: (asymptotic standard errors)
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.8181e-04 2.8039e-01 0.0010 0.999198
I(population/area) 5.9755e-05 1.8853e-05 3.1696 0.001527
Lambda: 0.64616, LR test value: 13.025, p-value: 0.00030728
Asymptotic standard error: 0.12127
z-value: 5.3282, p-value: 9.9192e-08
Wald statistic: 28.39, p-value: 9.9192e-08
Log likelihood: -39.81763 for error model
ML residual variance (sigma squared): 0.23562, (sigma: 0.48541)
Number of observations: 53
Number of parameters estimated: 4
AIC: 87.635, (AIC for lm: 98.661)AICでみると、OLSやSLMよりも当てはまりがよいです。
Spatial simultaneous autoregressive SAC model
SLMとSEMを合成したモデルを推定するsacsarlm関数が用意されています。今回は素朴なデータなので扱いません。
モデル選択
AICやBICを見る他、Lagrange Multiplier Testsができます。モデルの前提がかなり違うので、情報量規準や統計学的検定で選ばない方がよい気もしますが。
lm.LMtests(r_lm, listw = tokyo_cw, test = c("LMerr", "LMlag", "RLMerr", "RLMlag"), zero.policy=TRUE)
古いタイプの検定(Anselin (1988))と、頑強なタイプの検定(Anselin et al. (1996))がありますが、すべて同時に実行できます。
地理空間加重回帰モデル(GWR)の推定
観測点ごとに説明変数の係数が異なり、観測点と観測点が近いと似た、遠いと異なる係数になるモデルが地理空間加重回帰モデル(GWR)です*8。
観測点それぞれを中心にした距離に応じたウェイトを用いることで、観測点ごとに回帰分析をすることで、観測点ごとの係数を推定します。距離が近いと似たウェイトになり、距離が遠いと異なるウェイトになるのが仕掛けです。
ウェイトはガウシアン・カーネルで計算するので、ここまでの推定のために整備したリンク情報は要りません。
GWRの推定
spdepとspatialregではサポートされないようなので、spgwrパッケージを用います。ただし、ここまで作ってきたオブジェクトは再利用しているので、注意してください。
loadpkg("spgwr")
ポリゴンではなくポイントの座標を用いるので、推定にはプロットに使った市区町村の重心位置の座標が入ったデータフレームtokyo_centroidを再利用します。
model <- I(number.of.shrines/area) ~ I(population/area) # st_coordinatesはsfオブジェクトの座標データを行列にしてくれる。ポリゴンのように複数の座標で構成されていると複数の座標が戻るが、今回は1行1ポイントなのでgwr関数にそのまま流せる h <- gwr.sel(model, tokyo_centroid, coords = st_coordinates(tokyo_centroid)) # 交差検証によるバンド幅の決定 r_gwr <- gwr(model, tokyo_centroid, coords = st_coordinates(tokyo_centroid), bandwidth = h) # 定めたバンド幅の推定結果を計算
ガウシアンカーネルのバンド幅が上限に達してしまいますが、今回は気にしないことにします。
推定結果のプロット
市区町村の重心位置というポイントごとに推定量が出ているわけですが、市区町村のポリゴンでプロットしたいので、ポリゴンのデータに紐付けます。
# 推定に使ったポリゴンのデータセットに各地点のbeta_1の推定量を足す nb_datamap %>% mutate(beta = r_gwr$SDF[["I(population/area)"]]) -> nb_datamap # r_gwr$SDFはリスト構造
これでsfオブジェクトのプロットで係数を一望することができます。
ggplot() + geom_sf(data = nb_datamap, aes(fill = beta), color="darkgray") + scale_fill_gradient(low = "white", high = "green", name = "人口密度の係数") + labs(title = "人口密度が(本務)神社密度に与える影響", caption = "東京都神社庁のサイトと東京都の人口(推計)令和6年1月1日より編集", x = NULL, y = NULL)

なお、なにか綺麗な結果が得られている気がしますが、係数の絶対値の1/10000000単位の差異なので、おそらく何かの偶然です。
戻り値の取り扱い
なお、r_gwr$SDFはS4クラスSpatialPointsDataFrameになっており、sfオブジェクトもしくはデータフレームに変更した方が処理しやすいかもです。
# sfオブジェクトに変換する sdf_sf <- st_as_sf(r_gwr$SDF) # CRSがNAになるので設定する st_crs(sdf) <- st_crs(sdf) # データフレームに変換する sdf_df <- as.data.frame(r_gwr$SDF)
まとめ
Rによる地理空間データのプロットと地域空間計量モデルの推定をざっと試してみたのですが、10年前と比較して圧倒的に楽になっている気がします。sfパッケージの功績が大きいです。地理情報のある統計は多くあるので、有難く使っていきましょう。
*1:堤・瀬谷 (2012)「応用空間統計学の二つの潮流:空間統計学と空間計量経済学」数理統計,Vol.60(1), pp.3–25
*2:Rに例えばbrowseVignettes("sf")と打ち込むと、細かいところまで書いてある図つきのドキュメントがブラウザーで読めます。
*3:今回はSpatial Regressionを参考にしました。
*4:本稿では岩田真一郎「Rによる地理空間データの可視化」、高野佳佑「『事例で学ぶ経済・政策分析のためのGIS入門』のためのR入門:空間解析・可視化編」、古谷知之「環境ガバナンスのデータサイエンス/空間モデリング特論」などを参考にしました。
*5:CSV アドレス マッチング サービスを用いました。
*6:市区町村別に網羅的に数えたページがあり、そこのデータを使おうかなとも思ったのですが、ポイントデータと異なるデータになるのでやめました。
*7:式を整理すると誤差項がとなり、相互に誤差が伝播しあうことがモデル化されているのが分かります。なお、
の行列式は1未満が仮定されています。
*8:「空間データの回帰分析 (地理的加重回帰モデル) #R - Qiita」を参考にと言うか、一部分を請け売りしているだけです。